前言
我司的集群时刻处于崩溃的边缘,通过近三个月的掌握,发现我司的集群不稳定的原因有以下几点:
1、发版流程不稳定
2、缺少监控平台【最重要的原因】
3、缺少日志系统
4、极度缺少有关操作文档
5、请求路线不明朗
总的来看,问题的主要原因是缺少可预知的监控平台,总是等问题出现了才知道。次要的原因是服务器作用不明朗和发版流程的不稳定。
解决方案
发版流程不稳定
重构发版流程。业务全面k8s化,构建以kubernetes为核心的ci/cd流程。
发版流程
有关发版流程如下:
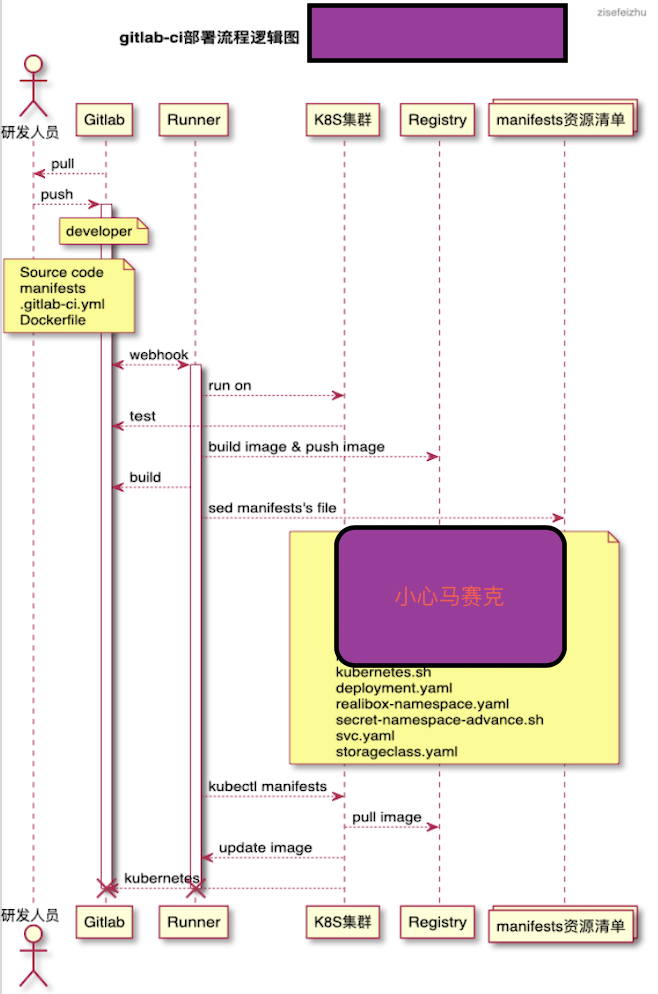
浅析:研发人员提交代码到developer分支(时刻确保developer分支处于最新的代码),developer分支合并到需要发版环境对应的分支,触发企业微信告警,触发部署在k8s集群的gitlab-runner pod,新启runner pod 执行ci/cd操作。在这个过程中需要有三个步骤:测试用例、打包镜像、更新pod。第一次部署服务在k8s集群环境的时候可能需要:创建namespace、创建imagepullsecret、创建pv(storageclass)、创建deployment(pod controller)、创建svc、创建ingress、等。其中镜像打包推送阿里云仓库和从阿里云仓库下载镜像使用vpc访问,不走公网,无网速限制。流程完毕,runner pod 销毁,gitlab 返回结果。
需要强调的一点是,在这里的资源资源清单不包含configmap或者secret,牵扯到安全性的问题,不应该出
现在代码仓库中,我司是使用rancher充当k8s多集群管理平台,上述安全问题在rancher的dashboard中由运维来做的。
服务部署逻辑图
有关服务部署逻辑图如下:
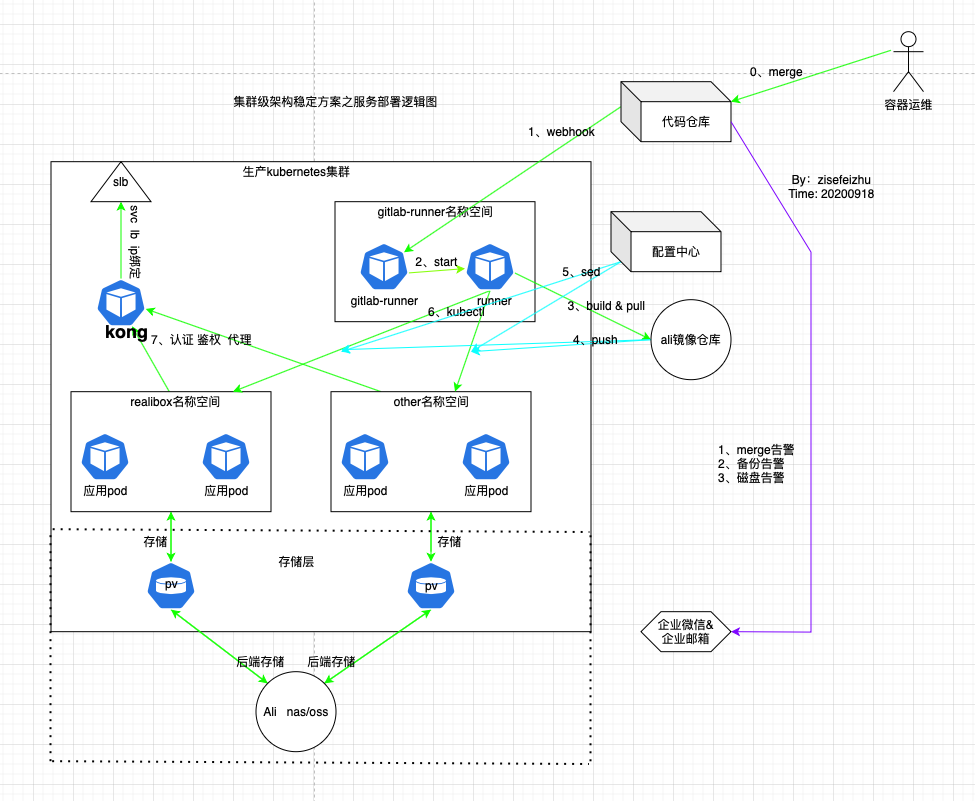
根据发版流程的浅析,再根据逻辑图可以明确发版流程。在这里看到我司使用的是kong代替nginx,做认证、鉴权、代理。而slb的ip绑定在kong上。0,1,2属于test job;3属于build job;4,5,6,7属于change pod 阶段。并非所有的服务都需要做存储,需要根据实际情况来定,所以需要在kubernetes.sh里写判断。在这里我试图使用一套CI应用与所有的环境,所以需要在kubernetes.sh中用到的判断较多,且.gitlab-ci.yml显得过多。建议是使用一个ci模版,应用于所有的环境,毕竟怎么省事怎么来。还要考虑自己的分支模式,具体参考:https://www.cnblogs.com/zisefeizhu/p/13621797.html
缺少监控预警平台
构建可信赖且符合我司集群环境的联邦监控平台,实现对几个集群环境的同时监控和预故障告警,提前介入。
监控预警逻辑图
有关监控预警逻辑图如下:
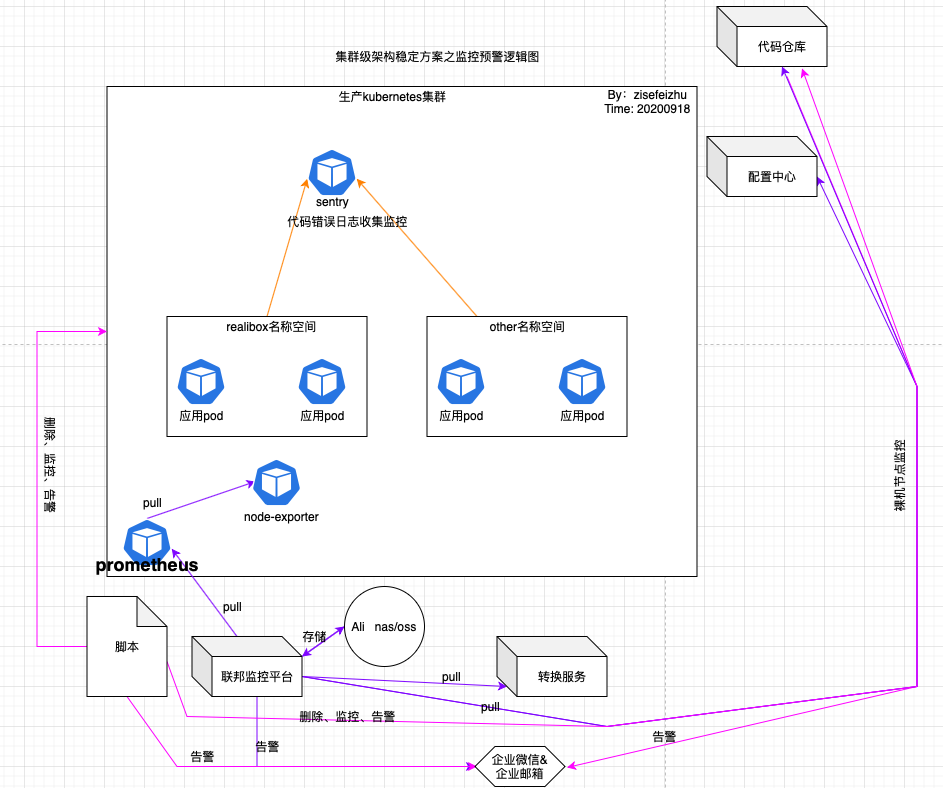
浅析:总的来说,我这里使用到的监控方案是prometheus➕shell脚本或go脚本➕sentry。使用到的告警方式是企业微信或者企业邮箱。上图三种颜色的线代表三种监控方式需要注意。脚本主要是用来做备份告警、证书告警、抓贼等。prometheus这里采用的是根据prometheus-opertor修改的prometheus资源清单,数据存储在nas上。sentry严格的来讲属于日志收集类的平台,在这里我将其归为监控类,是因为我看中了其收集应用底层代码的崩溃信息的能力,属于业务逻辑监控, 旨在对业务系统运行过程中产生的错误日志进行收集归纳和监控告警。
注意这里使用的是联邦监控平台,而部署普通的监控平台。
联邦监控预警平台逻辑图
多集群联邦监控预警平台逻辑图如下:
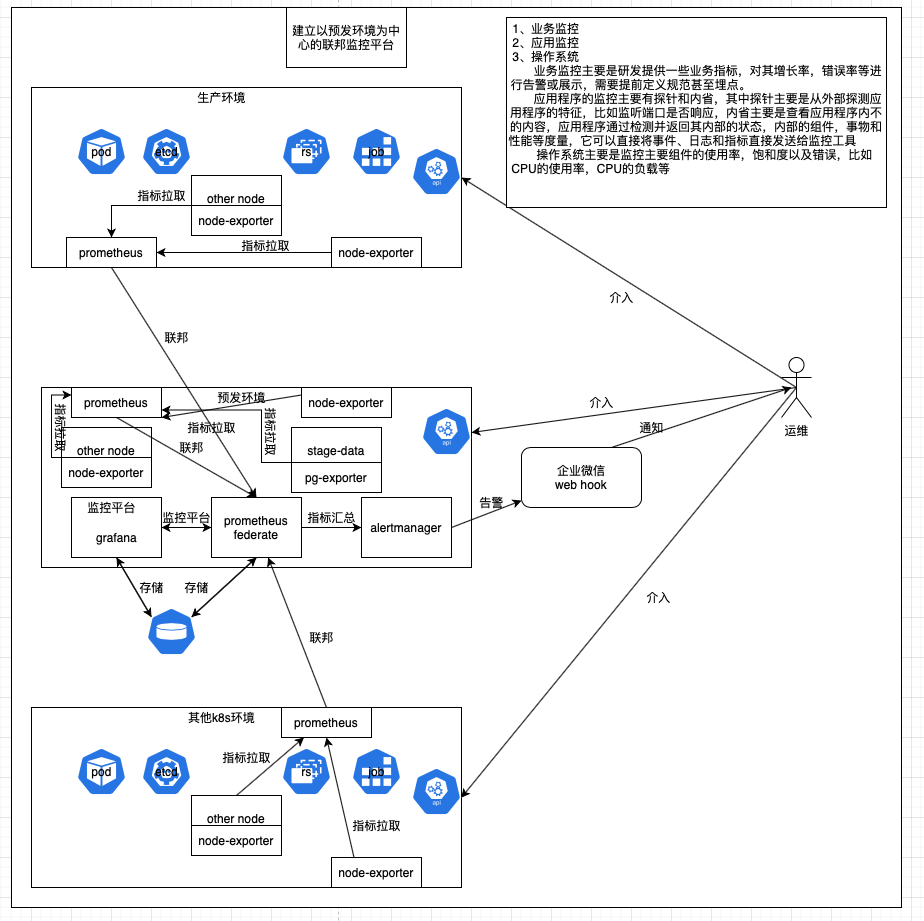
因为我司有几个k8s集群,如果在每个集群上都部署一套监控预警平台的话,管理起来太过不便,所以这里我采取的策略是使用将各监控预警平台实行一个联邦的策略,使用统一的可视化界面管理。这里我将实现三个级别饿监控:操作系统级、应用程序级、业务级。对于流量的监控可以直接针对kong进行监控,模版7424。
缺少日志系统
随着业务全面k8s化进程的推进,对于日志系统的需求将更加渴望,k8s的特性是服务的故障日志难以获取。建立可观测的能过滤的日志系统可以降低对故障的分析难度。
有关日志系统逻辑图如下:
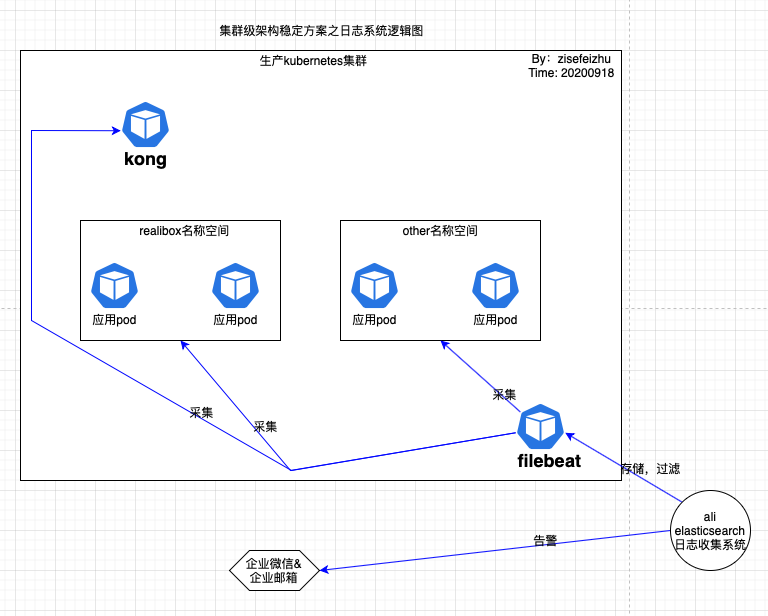
浅析:在业务全面上k8s化后,方便了管理维护,但对于日志的管理难度就适当上升了。我们知道pod的重启是有多因素且不可控的,而每次pod重启都会重新记录日志,即新pod之前的日志是不可见的。当然了有多种方法可以实现日志长存:远端存储日志、本机挂载日志等。出于对可视化、可分析等的考虑,选择使用elasticsearch构建日志收集系统。
极度缺少有关操作文档
建立以语雀--> 运维相关资料为中心的文档中心,将有关操作、问题、脚本等详细记录在案,以备随时查看。
浅析因安全性原因,不便于过多同事查阅。运维的工作比较特殊,安全化、文档化是必须要保障的。我认为不论是运维还是运维开发,书写文档都是必须要掌握的,为己也好,为他也罢。文档可以简写,但必须要含苞核心的步骤。我还是认为运维的每一步操作都应该记录下来。
请求路线不明朗
根据集群重构的新思路,重新梳理集群级流量请求路线,构建具备:认证、鉴权、代理、连接、保护、控制、观察等一体的流量管理,有效控制故障爆炸范围。
请求路线逻辑图如下:
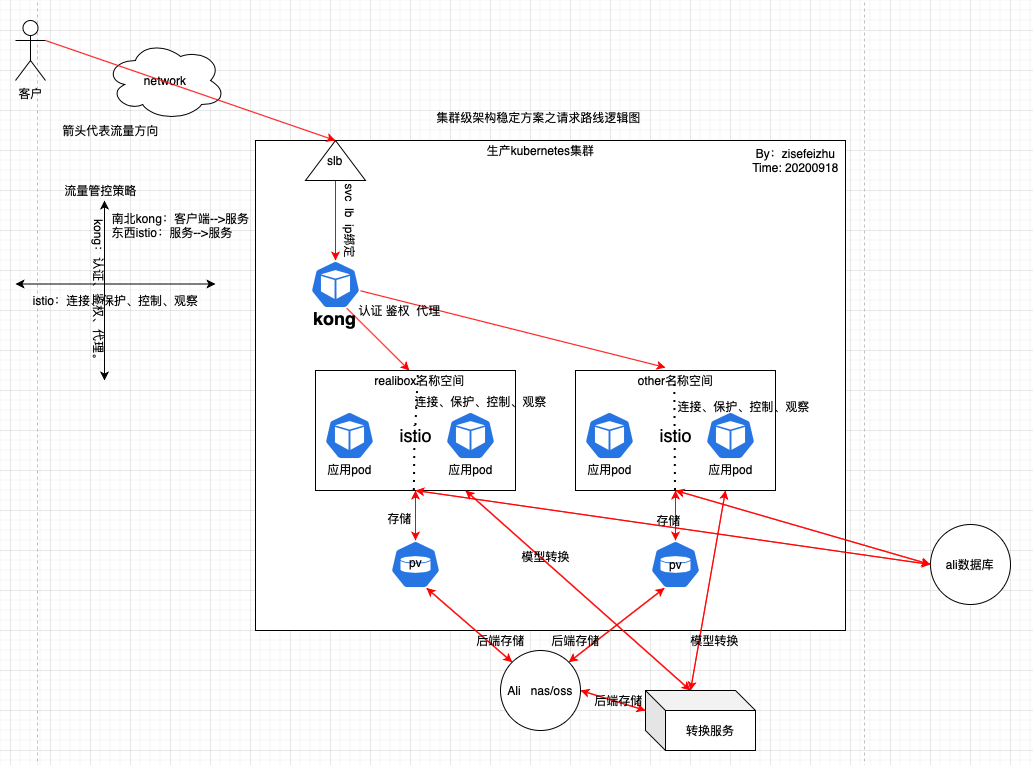
浅析:客户访问https://www.cnblogs.com/zisefeizhu 经过kong网关鉴权后进入特定名称空间(通过名称空间区分项目),因为服务已经拆分为微服务,服务间通信经过istio认证、授权,需要和数据库交互的去找数据库,需要写或者读存储的去找pv,需要转换服务的去找转换服务...... 然后返回响应。
总结
综上所述,构建以:以kubernetes为核心的ci/cd发版流程、以prometheus为核心的联邦监控预警平台、以elasticsearch为核心的日志收集系统、以语雀为核心的文档管理中心、以kong及istio为核心的南北东西流量一体化服务,可以在高平发,高可靠性上做到很好保障。
附:总体架构逻辑图
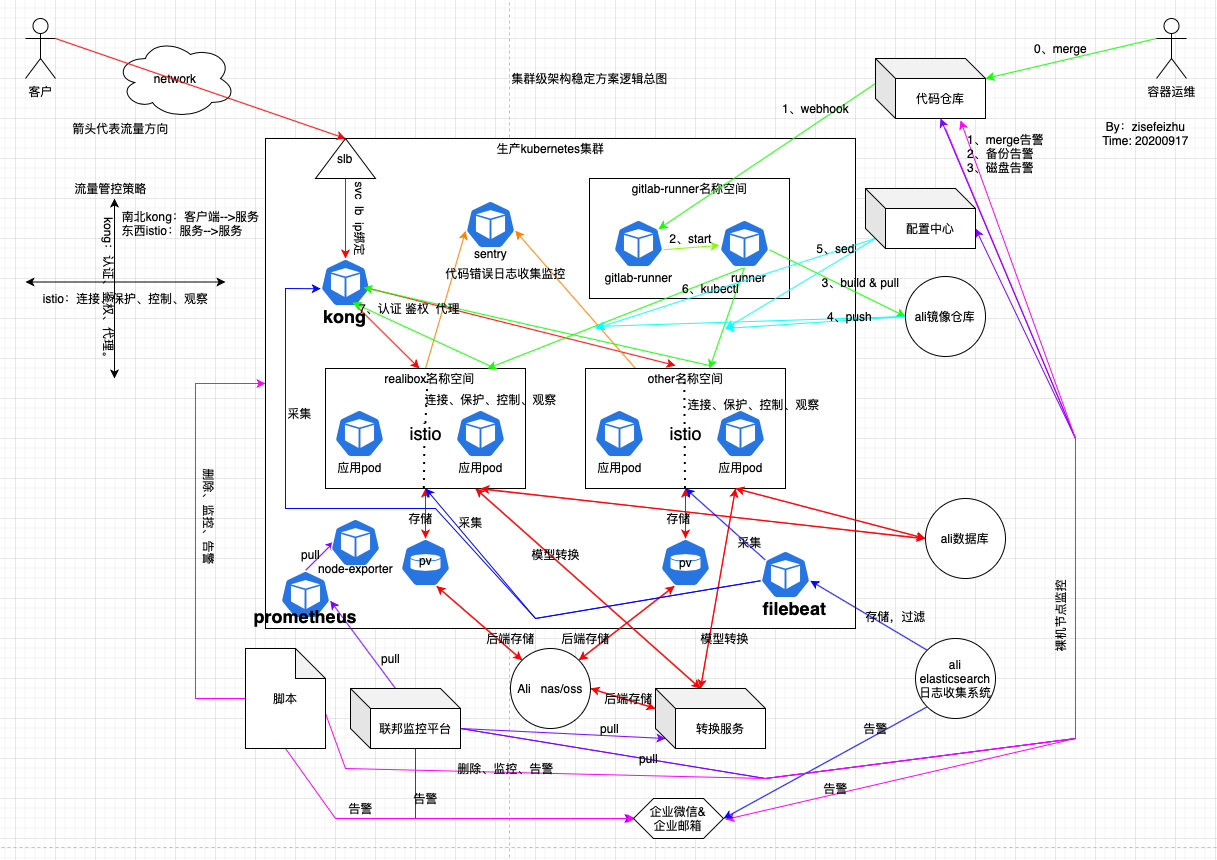
注:请根据箭头和颜色来分析。
浅析:上图看着似乎过于混乱,静下心来,根据上面的拆分模块一层层分析还是可以看清晰的。这里我用不同颜色的连线代表不同模块的系统,根据箭头走还是蛮清晰的。
根据我司目前的业务流量,上述功能模块,理论上可以实现集群的维稳。私认为此套方案可以确保业务在k8s集群上稳定的运行一段时间,再有问题就属于代码层面的问题了。这里没有使用到中间件,倒是使用到了缓存redis不过没画出来。我规划在上图搞定后再在日志系统哪里和转换服务哪里增加个中间件kafka或者rq 看情况吧。
原文转载:http://www.shaoqun.com/a/476414.html
五洲会:https://www.ikjzd.com/w/1068
淘粉吧怎么返利:https://www.ikjzd.com/w/1725
易联通:https://www.ikjzd.com/w/1854.html
亚马逊账号审核问题详解!:https://www.ikjzd.com/home/106804
避雷|哪些做法容易违反亚马逊图片要求?:https://www.ikjzd.com/home/117776
泽宝Sunvalley:https://www.ikjzd.com/w/1058
前言我司的集群时刻处于崩溃的边缘,通过近三个月的掌握,发现我司的集群不稳定的原因有以下几点:1、发版流程不稳定2、缺少监控平台【最重要的原因】3、缺少日志系统4、极度缺少有关操作文档5、请求路线不明朗总的来看,问题的主要原因是缺少可预知的监控平台,总是等问题出现了才知道。次要的原因是服务器作用不明朗和发版流程的不稳定。解决方案发版流程不稳定重构发版流程。业务全面k8s化,构建以kubernetes
勤商网:https://www.ikjzd.com/w/2219
aeo:https://www.ikjzd.com/w/2356
blackbird:https://www.ikjzd.com/w/950
900亿韩元!韩国向遭受新冠病毒影响的航运公司提供财政援助:https://www.ikjzd.com/home/117126
最新!律所又发案,侵权卖家做好准备!:https://www.ikjzd.com/home/103871
亚马逊为什么要退出中国市场,其中有什么隐情?:https://www.ikjzd.com/home/22972
没有评论:
发表评论